
인공지능 분야는 계속해서 빠르게 확장되고 있으며, 대규모 언어 모델(LLM)은 점점 더 정교한 인지 능력을 보여주고 있습니다. 그중에서도 FractalAIResearch/Fathom-R1-14B는 약 148억 개의 매개변수를 갖춘 주목할 만한 모델로 등장했습니다. 이 모델은 복잡한 수학 및 일반 추론 작업에서 탁월한 성능을 발휘하도록 Fractal AI Research에 의해 특별히 설계되었습니다. Fathom-R1-14B를 차별화하는 점은 놀라운 비용 효율성으로 실용적인 16,384 (16K) 토큰 컨텍스트 창 내에서 이러한 높은 수준의 성능을 달성할 수 있다는 것입니다. 이 글에서는 Fathom-R1-14B에 대한 기술적 개요를 제공하며, 개발 과정, 아키텍처, 학습 프로세스, 벤치마크 성능을 자세히 설명하고 기존 방법을 기반으로 한 실제 구현에 대한 집중적인 가이드를 제공합니다.
Fractal AI: 모델 뒤의 혁신가들

Fathom-R1-14B는 **Fractal AI Research**의 산물이며, Fractal AI Research는 **인도 뭄바이**에 본사를 둔 저명한 AI 및 분석 회사인 Fractal의 연구 부문입니다. Fractal은 Fortune 500대 기업에 인공지능 및 고급 분석 솔루션을 제공하여 전 세계적으로 명성을 얻었습니다. Fathom-R1-14B의 개발은 인공지능 분야에서 인도의 커지는 야망과 밀접하게 연관되어 있습니다.
인도의 AI 열망
이 모델의 개발은 **IndiaAI Mission**의 맥락에서 특히 중요합니다. Fractal의 공동 창립자이자 그룹 최고 경영자 및 부회장인 Srikanth Velamakanni는 Fathom-R1-14B가 더 큰 이니셔티브의 초기 시연이라고 밝혔습니다. 그는 "우리는 IndiaAI 미션의 일환으로 인도 최초의 대규모 추론 모델(LRM) 구축을 제안했습니다... 이 [Fathom-R1-14B]는 가능한 것의 작은 증거일 뿐입니다"라고 언급하며, 훨씬 더 큰 700억 개 매개변수 버전을 포함한 일련의 모델 계획을 암시했습니다. 이러한 전략적 방향은 AI 자립과 토착 기반 모델 생성에 대한 국가적 의지를 강조합니다. Fractal의 더 넓은 AI 기여에는 의료 지원을 위한 멀티모달 AI 플랫폼인 **Vaidya.ai**와 같은 다른 영향력 있는 프로젝트가 포함됩니다. 따라서 Fathom-R1-14B를 오픈 소스 도구로 출시하는 것은 전 세계 AI 커뮤니티에 이익이 될 뿐만 아니라 인도의 진화하는 AI 환경에서 핵심적인 성과를 의미합니다.
Fathom-R1-14B의 기반 설계 및 아키텍처 청사진
Fathom-R1-14B의 인상적인 기능은 신중하게 선택된 기반과 추론 작업에 최적화된 견고한 아키텍처 설계 위에 구축되었습니다.
Fathom-R1-14B의 여정은 Deepseek-R1-Distilled-Qwen-14B를 기본 모델로 선택하면서 시작되었습니다. 이 모델의 "증류된(distilled)" 특성은 더 큰 상위 모델의 더 작고 계산 효율적인 파생 모델로서, 특히 평판이 좋은 Qwen 계열의 기능을 상당 부분 유지하도록 특별히 설계되었음을 의미합니다. 이는 강력한 출발점을 제공했으며, Fractal AI Research는 전문적인 후처리 학습 기법을 통해 이를 세심하게 개선했습니다. 작동을 위해 모델은 일반적으로 계산 속도와 복잡한 계산에 필요한 수치 정확도 사이에서 효과적인 균형을 이루는 **bfloat16 (Brain Floating Point Format)** 정밀도를 사용합니다.
Fathom-R1-14B는 Transformer 모델 계열 내의 강력한 반복인 **Qwen2 아키텍처** 위에 구축되었습니다. Transformer 모델은 혁신적인 **자기 주의(self-attention) 메커니즘** 덕분에 고성능 LLM의 현재 표준입니다. 이러한 메커니즘을 통해 모델은 출력을 생성할 때 입력 시퀀스 내의 다양한 토큰(단어, 하위 단어 또는 수학 기호)의 중요성을 동적으로 가중치를 부여할 수 있습니다. 이 능력은 복잡한 수학 문제와 미묘한 논리적 주장 내에 존재하는 복잡한 종속성을 이해하는 데 중요합니다.
약 **148억 개의 매개변수**로 특징지어지는 모델의 규모는 성능의 핵심 요소입니다. 이러한 매개변수는 본질적으로 신경망 계층 내에서 학습된 수치 값으로, 모델의 지식과 추론 능력을 인코딩합니다. 이 규모의 모델은 학습 데이터에서 복잡한 패턴을 포착하고 표현하는 데 상당한 용량을 제공합니다.
16K 컨텍스트 창의 중요성
중요한 아키텍처 사양은 **16,384 토큰 컨텍스트 창**입니다. 이는 단일 작업에서 처리할 수 있는 입력 프롬프트와 모델 생성 출력의 총 최대 길이를 결정합니다. 일부 모델은 훨씬 더 큰 컨텍스트 창을 자랑하지만, Fathom-R1-14B의 16K 용량은 의도적이고 실용적인 설계 선택입니다. 이는 상세한 문제 설명, 광범위한 단계별 추론 과정(올림피아드 수준 수학에서 자주 요구됨), 그리고 포괄적인 답변을 수용하기에 충분히 큽니다. 중요하게도, 이는 매우 긴 시퀀스의 주의 메커니즘과 관련된 계산 비용의 2차적 증가 없이 달성되어, 추론 시 Fathom-R1-14B를 더 민첩하고 자원 소모가 적게 만듭니다.
Fathom-R1-14B는 정말 **비용 효율적입니다
Fathom-R1-14B의 가장 두드러진 측면 중 하나는 후처리 학습 과정의 효율성입니다. 모델의 주요 버전은 약 **499 USD**의 비용으로 미세 조정되었다고 보고되었습니다. 이러한 놀라운 경제적 타당성은 과도한 계산 비용 없이 추론 기술을 극대화하는 데 초점을 맞춘 정교하고 다면적인 학습 전략을 통해 달성되었습니다.
이러한 효율적인 전문화를 뒷받침하는 핵심 기술은 다음과 같습니다:
- 지도 미세 조정(SFT): 이 기초 단계에서는 고급 수학적 추론에 특별히 맞춤화된 문제-해결 쌍의 고품질 선별 데이터셋으로 기본 모델을 학습시켰습니다. SFT를 통해 모델은 올바른 문제 해결 경로와 논리적 추론을 모방하는 방법을 배웠습니다.
- 반복 커리큘럼 학습: 이 전략은 모델을 한 번에 전체 난이도 스펙트럼에 노출시키는 대신, 단계적으로 과제를 도입합니다. 모델은 더 간단한 수학 문제로 시작하여 AIME 및 HMMT와 같은 더 복잡한 문제로 점진적으로 이동합니다. 이러한 구조화된 접근 방식은 모델이 매우 어려운 작업을 다루기 전에 강력한 기반을 구축할 수 있도록 하여 더 안정적이고 효과적인 학습을 촉진합니다. 이 기법은 핵심 전신 모델인
Fathom-R1-14B-V0.6개발의 중심이었습니다. - 모델 병합: 최종 Fathom-R1-14B 모델은 두 개의 특정 미세 조정된 전신 모델의 결합입니다:
Fathom-R1-14B-V0.6(반복 커리큘럼 SFT를 거친 모델) 및Fathom-R1-14B-V0.4("Shortest-Chains"를 사용한 SFT에 중점을 둔 모델로, 아마도 솔루션의 간결성을 강조했을 것입니다). 약간 다른 초점으로 학습된 모델을 병합함으로써 결과 모델은 더 넓은 범위의 강점을 상속받습니다.
이 세심한 학습 과정의 전반적인 목표는 "간결하면서도 정확한 수학적 추론"을 주입하는 것이었습니다.
Fractal AI Research는 Fathom-R1-14B-RS라는 변형 모델로 대체 학습 경로도 탐색했습니다. 이 버전은 SFT와 함께 **강화 학습(RL)**, 특히 GRPO(Generalized Reward Pushing Optimization)라고 불리는 알고리즘을 통합했습니다. 이 접근 방식은 비교 가능한 높은 성능을 보였지만, 후처리 학습 비용은 약 **967 USD**로 약간 더 높았습니다. 두 버전 모두의 개발은 효율적으로 최적의 추론 성능을 달성하기 위한 다양한 방법론 탐색에 대한 의지를 강조합니다. 투명성에 대한 약속의 일환으로, Fractal AI Research는 학습 레시피와 데이터셋을 오픈 소스로 공개했습니다.
성능 벤치마크: 추론 우수성 정량화
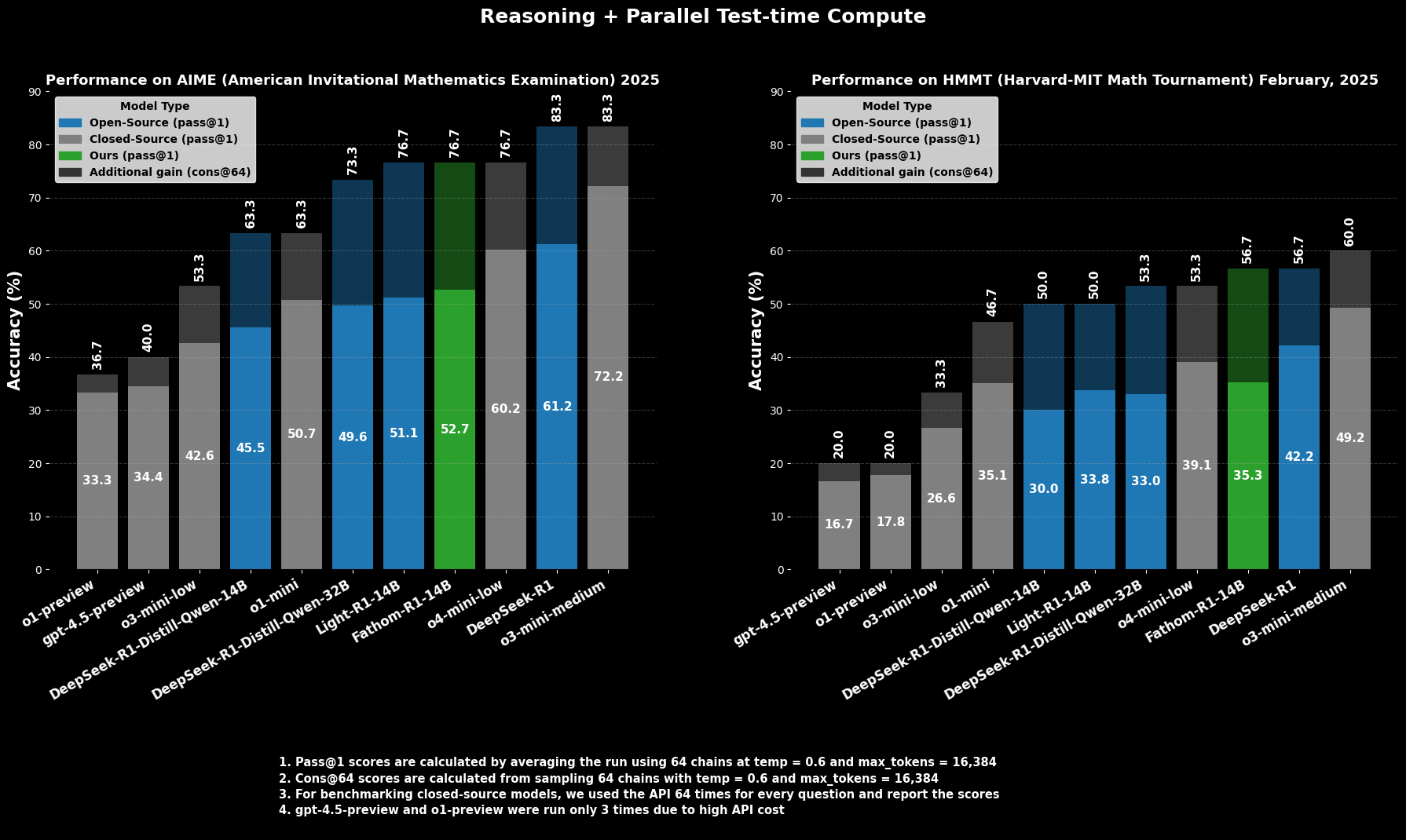
Fathom-R1-14B의 숙련도는 단순히 이론적인 것이 아니라, 엄격하고 국제적으로 인정받는 수학적 추론 벤치마크에서 인상적인 성능으로 입증되었습니다.
AIME 및 HMMT에서의 성공
도전적인 대학 예비 수학 경시 대회인 **AIME2025 (American Invitational Mathematics Examination)**에서 Fathom-R1-14B는 **Pass@1 정확도 52.71%**를 달성했습니다. Pass@1 메트릭은 모델이 단 한 번의 시도로 올바른 솔루션을 생성한 문제의 비율을 나타냅니다. 테스트 시 더 많은 계산 예산이 허용될 때, **cons@64** (64개 샘플링된 솔루션 간의 일관성)를 사용하여 평가하면 AIME2025에서의 정확도는 인상적인 **76.7%**로 상승합니다.
마찬가지로, 또 다른 고수준 경시 대회인 **HMMT25 (Harvard-MIT Mathematics Tournament)**에서 모델은 **Pass@1 35.26%**를 기록했으며, 이는 **cons@64 56.7%**로 증가합니다. 이러한 점수는 모델의 16K 토큰 출력 예산 내에서 달성되었다는 점에서 특히 주목할 만하며, 실제 배포 고려 사항을 반영합니다.
비교 성능
비교 평가에서 Fathom-R1-14B는 Pass@1에서 이러한 특정 수학 벤치마크에서 유사하거나 심지어 더 큰 규모의 다른 오픈 소스 모델보다 훨씬 뛰어난 성능을 보입니다. 더욱 놀라운 것은, 특히 cons@64 메트릭을 고려할 때, 그 성능은 종종 훨씬 더 많은 자원에 접근할 수 있다고 추정되는 일부 유능한 비공개 소스 모델과 경쟁할 만한 위치에 있다는 것입니다. 이는 Fathom-R1-14B가 매개변수와 학습을 고충실도 추론으로 변환하는 효율성을 강조합니다.
Fathom-R1-14B를 실행해 봅시다
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
이 섹션에서는 Python 환경 내에서 Hugging Face transformers 라이브러리를 사용하여 Fathom-R1-14B를 실행하는 데 대한 집중적인 가이드를 제공합니다. 이 접근 방식은 로컬 또는 클라우드 제공업체를 통해 유능한 GPU 하드웨어에 접근할 수 있는 사용자에게 적합합니다. 여기에 설명된 단계는 이러한 모델을 배포하기 위한 기존 관행을 면밀히 따릅니다.
환경 설정
적절한 Python 환경을 설정하는 것이 중요합니다. 다음 단계는 Linux 기반 시스템(또는 Windows Subsystem for Linux)에서 Conda를 사용한 일반적인 설정 방법을 자세히 설명합니다.
머신 접근: 원격 클라우드 GPU 인스턴스를 사용하는 경우 SSH를 통해 연결합니다.Bash
# Example: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
GPU 인식 확인: 시스템이 NVIDIA GPU를 인식하고 드라이버가 올바르게 설치되었는지 확인합니다.Bash
nvidia-smi
Conda 환경 생성 및 활성화: 프로젝트 종속성을 격리하는 것이 좋습니다.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
필요 라이브러리 설치: PyTorch(CUDA 버전과 호환되는), Hugging Face transformers, accelerate(효율적인 모델 로딩 및 분산용), notebook(Jupyter용), 그리고 ipywidgets(노트북 상호 작용용)를 설치합니다.Bash
# Ensure you install a PyTorch version compatible with your GPU's CUDA toolkit
# Example for CUDA 11.8:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Or for CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Jupyter Notebook에서 Python 기반 추론
환경이 준비되면 Jupyter Notebook을 사용하여 Fathom-R1-14B를 로드하고 상호 작용할 수 있습니다.
Jupyter Notebook 서버 시작: 원격 서버에 있는 경우 원격 접근을 허용하고 포트를 지정하여 Jupyter Notebook을 시작합니다.Bash
jupyter notebook --no-browser --port=8888 --allow-root
원격으로 실행하는 경우, Jupyter 인터페이스에 접근하기 위해 로컬 머신에서 SSH 포트 포워딩을 설정해야 할 수 있습니다:Bash
# Example: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
그런 다음 웹 브라우저에서 http://localhost:8889 (또는 선택한 로컬 포트)를 엽니다.
모델 상호 작용을 위한 Python 코드: 새 Jupyter Notebook을 만들고 다음 Python 코드를 사용합니다:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Define the model ID from Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Loading tokenizer for {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Loading model {model_id} (this may take a while)...")
# Load the model with bfloat16 precision for efficiency and device_map for auto distribution
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it
device_map="auto", # Automatically distributes model layers across available hardware
trust_remote_code=True # Some models may require this
)
print("Model and tokenizer loaded successfully.")
# Define a sample mathematical prompt
prompt = """Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. In June, she sold 4 more clips than in May. How many clips did Natalia sell altogether in April, May, and June? Provide a step-by-step solution.
Solution:"""
print(f"\nPrompt:\n{prompt}")
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Ensure inputs are on the model's device
print("\nGenerating solution...")
# Generate the output from the model
# Adjust generation parameters as needed for different types of problems
outputs = model.generate(
**inputs,
max_new_tokens=768, # Maximum number of new tokens to generate for the solution
num_return_sequences=1, # Number of independent sequences to generate
temperature=0.1, # Lower temperature for more deterministic, factual outputs
top_p=0.7, # Use nucleus sampling with top_p
do_sample=True # Enable sampling for temperature and top_p to have an effect
)
# Decode the generated tokens into a string
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerated Solution:\n")
print(solution_text)
결론: Fathom-R1-14B가 접근 가능한 AI에 미치는 영향
FractalAIResearch/Fathom-R1-14B는 현대 AI 분야에서 기술적 독창성의 설득력 있는 시연으로 자리매김합니다. 약 **148억 개의 매개변수**, **Qwen2 아키텍처**, 그리고 **16K 토큰 컨텍스트 창**을 특징으로 하는 특정 설계는 획기적이고 비용 효율적인 학습(주요 버전의 경우 약 **499 달러**)과 결합되어 최첨단 성능을 제공하는 LLM을 탄생시켰습니다. 이는 AIME 및 HMMT와 같은 고난이도 수학적 추론 벤치마크에서의 점수로 입증됩니다.
Fathom-R1-14B는 지능적인 설계와 효율적인 방법론을 통해 AI 추론의 경계를 발전시킬 수 있으며, 고성능 AI가 더욱 민주화되고 광범위하게 유익한 미래를 조성함을 설득력 있게 보여줍니다.
최대 생산성으로 개발팀이 함께 작업할 수 있는 통합된 올인원 플랫폼을 원하십니까?
Apidog는 귀하의 모든 요구 사항을 충족하며, Postman을 훨씬 더 저렴한 가격으로 대체합니다!